
W pracy na dużych korporacyjnych środowiskach bazodanowych optymalizacja zapytań SQL staje się kluczowa, zwłaszcza gdy nieoptymalne zapytania obciążają system i spowalniają pracę innych użytkowników. Winowajcami takiego stanu rzeczy mogą być m.in. braki odpowiednich testów lub sytuacja, w której ktoś otrzymuje zapytanie od innej osoby, z którym woli nic nie grzebać, żeby nie popsuć czegoś, co choć działa wolno, to jednak działa. Nic tak jednak nie frustruje użytkowników platform danych, jak powolna baza danych, która opóźnia prace całego zespołu. Do tego mamy jeszcze z tyłu głowy, że trzymają nas napięte terminy związane ze zbliżającym się raportowaniem. Jak temu zaradzić?
Przygotowałem dla Ciebie rozwiązanie. Poniżej znajdziesz opis 13 kluczowych technik optymalizacji zapytań SQL, które pomogą Ci w:
- Zmniejszeniu obciążenia serwera i poprawieniu jego wydajności
- Znacznemu przyspieszeniu Twoich zapytań i zwiększeniu efektywności pracy
- Szybkim znalezieniu i wyeliminowaniu wąskich gardeł w Twoich procesach bazodanowych
- Skupieniu się na tym co naprawdę ważne, czyli rozwijaniu nowych projektów i osiąganiu celów.
Szybki Przegląd
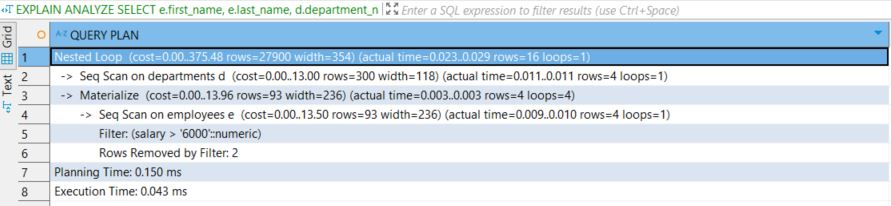
Korzystaj z EXPLAIN! Dlaczego plan wykonania to Twój najlepszy przyjaciel?
Przed uruchomieniem zapytania, w szczególności jeśli uruchamiasz je po raz pierwszy, dodaj EXPLAIN przed zapytaniem. Otrzymasz w odpowiedzi plan zapytania, który pomoże zidentyfikować wąskie gardła Twojego zapytania – od pełnych skanowań tabel, przez brak użycia indeksów, aż po nieoptymalne JOIN-y. Poświęć czas na analizę wygenerowanego planu, znajdź i napraw wskazane problemy wydajnościowe, zanim zamienią się w prawdziwe bóle głowy! Pamiętaj optymalizacja zapytań SQL zaczyna się od poznania jak działa dane zapytanie.
EXPLAIN ANALYZE SELECT e.first_name, e.last_name, d.department_name FROM employees e, departments d WHERE e.salary > 6000;
Unikaj SELECT *! Wybieraj tylko potrzebne kolumny i zyskuj szybkość
Stosowanie SELECT * jest jak zaproszenie całego biura na spotkanie, gdy potrzebujesz porozmawiać tylko z jedną osobą – niby działa, ale jest zupełnie nieefektywne. Gdy używasz SELECT * baza danych pobiera wszystkie kolumny z tabeli. Zamiast tego, wybieraj tylko te kolumny, które faktycznie są Ci potrzebne. Dzięki temu skrócisz czas wykonania zapytań SQL, zmniejszysz obciążenie serwera i zoptymalizujesz zużycie zasobów. Pamiętaj optymalizacja zapytań SQL to przede wszystkim odpytywanie mniejszej ilości danych co oznacza większa szybkość wykonania zapytania.
--Nieoptymalny przykład SELECT * FROM employees WHERE salary > 6000;
--Optymalny przykład SELECT first_name, last_name FROM employees WHERE salary > 6000;
Najpierw filtruj, potem licz! Czyli dlaczego WHERE bije HAVING na głowę
Dlaczego WHERE jest lepsze?
- Filtrowanie jako pierwsze: WHERE działa przed grupowaniem danych, co oznacza, że baza danych przetwarza mniej wierszy w późniejszych etapach zapytania.
- Optymalizacja wydajności: Przeniesienie warunków filtrowania do WHERE zmniejsza ilość danych, które muszą być grupowane i agregowane, co przyspiesza całe zapytanie.
Pamiętaj, aby zawsze myśleć o filtrach jako pierwszym kroku w optymalizacji!
Używaj HAVING, gdy musisz zastosować warunki na wynikach agregacji, które nie są możliwe do wykonania w WHERE.
--Nieoptymalny przykład. Filtracja w HAVING SELECT department_id FROM employees GROUP BY department_id HAVING COUNT(department_id) < 0;
--Optymalny przykład. Filtracja w WHERE SELECT department_id FROM employees WHERE department_id IS NOT NULL GROUP BY department_id;
Statystyki w SQL: Opieraj się na liczbach i wyciągaj wnioski
Statystyki w bazach danych są jak GPS dla Twoich zapytań SQL – pomagają zoptymalizować wydajność, pokazując, jak najlepiej uzyskać dostęp do danych. Optymalizacja zapytań SQL polega w tym przypadku na regularnym aktualizowaniu i monitorowaniu statystyk, które mogą znacznie poprawić szybkość działania bazy danych.
Jak zarządzać statystykami w SQL:
- Aktualizuj statystyki regularnie: Bazy danych używają statystyk do oceny, tego jak efektywnie można przeszukać dane. Utrzymywanie statystyk na bieżąco zapewnia, że optymalizator zapytań ma najbardziej aktualne informacje do podejmowania decyzji.
- Używaj narzędzi do analizy: Większość systemów zarządzania bazami danych oferuje narzędzia i komendy do ręcznej aktualizacji statystyk (np. ANALYZE w PostgreSQL, UPDATE STATISTICS w Microsoft SQL Server). Regularne ich uruchamianie zapewnia, że zapytania są optymalizowane zgodnie z rzeczywistym rozkładem danych.
- Monitoruj wydajność: Śledź zmiany w wydajności po aktualizacji statystyk, aby upewnić się, że przynoszą one pożądane efekty. Warto zwrócić uwagę na zapytania, które uległy poprawie lub pogorszeniu.
Dobre rady:
- Regularność: Ustal harmonogram aktualizacji statystyk, szczególnie po dużych operacjach INSERT, UPDATE, DELETE
- Zrozumienie danych: Rozumienie rozkładu danych w tabelach pomaga lepiej zarządzać statystykami i dostosowywać zapytania.
Wykorzystując statystyki, możesz poprawić wydajność zapytań SQL, zapewniając, że są one optymalizowane na podstawie najbardziej aktualnych danych. To kluczowy krok w utrzymaniu bazy danych w doskonałej kondycji.

Partycjonowanie – kiedy Twoja tabela jest zbyt duża, by ją zjeść na raz
Partycjonowanie tabel w SQL jest jak podział dużego zadania na mniejsze, łatwiejsze do zarządzania kawałki. Dzięki temu Twoje zapytania mogą działać szybciej i bardziej efektywnie. Każda partycja jest traktowana jako oddzielna jednostka, co może przyspieszyć operacje odczytu, zapisu i zarządzania danymi.
Korzyści z partycjonowania:
- Szybsze zapytania: Jeśli zapytanie dotyczy tylko jednej partycji, baza danych nie musi przeszukiwać całej tabeli. To znacząco przyspiesza operacje na dużych zestawach danych.
- Lepsze zarządzanie: Możesz łatwiej zarządzać danymi, np. archiwizować lub usuwać stare partycje bez wpływu na resztę tabeli.
- Poprawa wydajności: Partycjonowanie może poprawić wydajność operacji takich jak SELECT, UPDATE i DELETE, zwłaszcza gdy operują one na dużych zbiorach danych.
Jak wdrożyć partycjonowanie:
- Wybór klucza partycjonowania: Wybierz kolumnę, na podstawie której będziesz dzielić tabelę, np. datę czy kategorię produktu.
- Używanie indeksów na partycjonowanych kolumnach: Upewnij się, że kolumny używane do partycjonowania są dobrze zaindeksowane, co pomoże w szybkim przeszukiwaniu i łączeniu danych.
- Utrzymanie partycji: Regularnie monitoruj i zarządzaj partycjami, np. dodawaj nowe partycje w miarę upływu czasu lub usuwaj stare dane.
--Przykład utworzenia tabeli partycjonowanej
CREATE TABLE employees1 (
employee_id SERIAL,
first_name VARCHAR(50),
last_name VARCHAR(50),
salary DECIMAL(10, 2),
department_id INT,
created_at DATE NOT NULL,
PRIMARY KEY (employee_id, created_at)
) PARTITION BY RANGE (created_at);
CREATE TABLE employees1_2023 PARTITION OF employees
FOR VALUES FROM ('2023-01-01') TO ('2024-01-01');
CREATE TABLE employees1_2024 PARTITION OF employees
FOR VALUES FROM ('2024-01-01') TO ('2025-01-01');
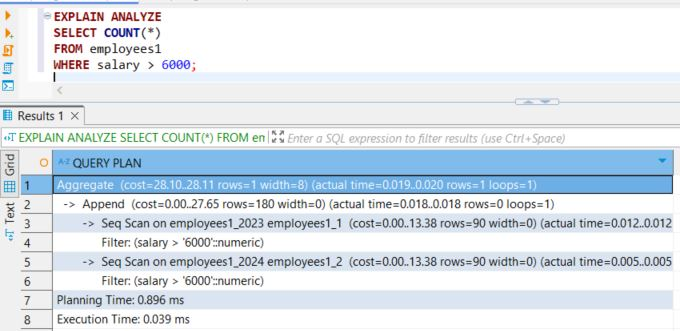
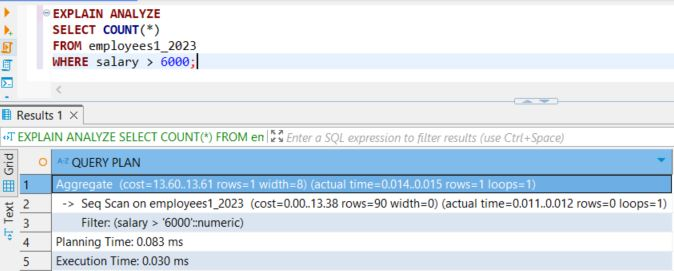
Dodatkowe wskazówki:
- Testuj partycjonowanie: Zawsze testuj partycjonowanie w środowisku testowym, aby zobaczyć, jak wpływa na wydajność i jak najlepiej skonfigurować partycje dla swoich danych.
- Zrozumienie danych: Znajomość rozkładu danych pomoże w lepszym wyborze klucza partycjonowania.
Indeksy – Twoje tajne kody do szybkości! Jak i kiedy z nich korzystać?
Indeksy to jak turbo doładowanie dla Twojej bazy danych – pomagają szybko znaleźć potrzebne dane, zamiast przeszukiwać każdą komórkę tabeli. Używaj indeksów na kolumnach, które często pojawiają się w klauzulach WHERE, JOIN, ORDER BY i GROUP BY.
Pamiętaj jednak: nie przesadzaj z ilością! Każdy indeks zajmuje miejsce na dysku i spowalnia operacje INSERT, UPDATE, DELETE. Zastanów się, które kolumny rzeczywiście potrzebują indeksów i twórz je rozważnie. Najważniejszy jest balans: właściwie dobrane indeksy to klucz do szybkości, zaś ich nadmiar to krok do spowolnienia. Indeksuj mądrze!

JOIN-y jak puzzle – naucz się je układać jak mistrz i przyspiesz swoje zapytania
Optymalizacja JOIN-ów to jak układanie skomplikowanego puzzle – jeśli zrobisz to źle, efekt będzie rozczarowujący. Oto kluczowe wskazówki:
- Indeksy na kolumnach JOIN: Jeśli możesz zrób tak, aby kolumny, które łączysz, były indeksami. Indeksy na kolumnach używanych w JOIN-ach przyspieszają łączenie tabel.
- Ogranicz liczbę JOIN-ów: Staraj się unikać zbyt wielu JOIN-ów w jednym zapytaniu. Zamiast tego rozważ podział na mniejsze zapytania lub optymalizację tabel.
- Oceń dokładnie jakich danych potrzebujesz: Jeśli to możliwe korzystaj z INNER JOIN zamiast LEFT/RIGHT/OUTER JOIN. INNER JOIN zwykle daje optymalną wydajność w porównaniu z innymi typami JOIN-ów.
--Staraj się zapisywać złączenia korzystając ze składni JOIN ON. --Przypadek 1 jest czytelniejszy niż Przypadek 2, ponieważ wskazuje jednoznacznie, że mamy do czynienia ze złączeniem. --Przypadek 1 SELECT e.first_name, e.last_name, d.department_name FROM employees e JOIN departments d ON e.department_id = d.department_id; --Przypadek 2 SELECT e.first_name, e.last_name, d.department_name FROM employees e, departments d WHERE e.department_id = d.department_id;
Unikaj iloczynów kartezjańskich
Iloczyn kartezjański, czyli „cross join”, to operacja w SQL, która łączy każdą kombinację wierszy z dwóch tabel. Choć może być użyteczny w pewnych przypadkach, często prowadzi do nieprzewidzianych i kosztownych wyników.
Dlaczego unikać iloczynów kartezjańskich:
- Ogromne zestawy danych: Jeśli jedna tabela ma 1 000 wierszy, a druga 2 000 wierszy, iloczyn kartezjański wygeneruje 2 000 000 wierszy – to ogromne obciążenie dla bazy danych.
- Problemy z wydajnością: Duże zestawy danych mogą spowodować, że zapytania będą działać bardzo wolno lub nawet nie wykonają się z powodu braku pamięci.
Jak unikać iloczynów kartezjańskich:
- Używaj klauzuli JOIN z warunkami: Zamiast wykonywać iloczyn kartezjański, zawsze używaj INNER JOIN, LEFT JOIN itp., z odpowiednimi warunkami, aby łączyć tabele na podstawie wspólnych kolumn.
- Weryfikacja planu wykonania: Używaj narzędzi takich jak EXPLAIN (w MySQL) lub EXPLAIN ANALYZE (w PostgreSQL) do analizy planu wykonania zapytania. Sprawdź, czy zapytanie nie generuje iloczynu kartezjańskiego i dostosuj je w razie potrzeby.
- Przemyśl zapytania: Zastanów się, czy naprawdę potrzebujesz łączyć wszystkie wiersze z obu tabel. Może warto skorzystać z filtrów, agregacji lub innych technik, które mogą ograniczyć liczbę przetwarzanych danych.
--Nieoptymalny przykład. Brak warunku JOIN prowadzi do iloczynu kartezjańskiego, co skutkuje ogromną ilością rekordów. SELECT * FROM employees, departments; --Tabela employees ma 6 rekordów --Tabela departments ma 4 rekordy --Kombinacja każdego wiersza z employees oraz departments daje nam 6 x 4 = 24 rekordy --Przy ogromnych tabelach operacja jest bardzo obciążająca dla silnika bazy danych
--Optymalny przykład SELECT * FROM employees e JOIN departments d ON e.department_id = d.department_id;
Unikając iloczynów kartezjańskich, możesz zaoszczędzić czas i zasoby serwera, przyspieszając działanie zapytań i unikając problemów związanych z wydajnością. Dbałość o to, jak łączysz tabele, jest kluczowa dla utrzymania bazy danych w dobrej kondycji.
Podzapytania – Twoje ukryte hamulce. Kiedy je omijać, a kiedy z nich korzystać?
Podzapytania (subqueries) w SQL mogą być jak sekretne hamulce w Twoich zapytaniach – używane nieumiejętnie mogą znacznie spowolnić działanie.
Jak efektywnie używać podzapytań:
- Najlepiej zamień je na JOIN: Często podzapytania w klauzuli WHERE można zastąpić JOIN-ami. JOIN-y są zazwyczaj bardziej efektywne, ponieważ baza danych może lepiej optymalizować takie operacje.
- Używaj podzapytań w SELECT ostrożnie: Podzapytania w klauzuli SELECT mogą być kosztowne, ponieważ są wykonywane dla każdego wiersza głównego zapytania. Staraj się używać ich tylko wtedy, gdy są absolutnie niezbędne.
- Ogranicz wyniki podzapytań: Jeśli musisz używać podzapytań, ogranicz wyniki do minimalnej liczby wierszy i kolumn, aby zmniejszyć obciążenie.
Kiedy używać podzapytań:
- Gdy zapytanie wymaga specyficznych, złożonych warunków, które są trudne do wyrażenia w prostych JOIN-ach.
- Jeśli bazowy plan wykonania pokazuje, że podzapytanie jest dobrze zoptymalizowane.
--Nieoptymalny przykład. Użycie podzapytania
SELECT name
FROM employees
WHERE department_id IN (
SELECT department_id
FROM departments
WHERE department_name = 'Sales');
--Optymalny przykład. Użycie join SELECT e.name FROM employees e JOIN departments d ON e.department_id = d.department_id WHERE d.department_name = 'Sales';
Funkcje w WHERE i JOIN? Unikaj ich jak ognia.
Funkcje w klauzulach WHERE i JOIN mogą spowolnić Twoje zapytania SQL. Optymalizacja zapytań SQL w przypadku funkcji sprowadza się do ich unikania podczas filtrowania rekordów w WHERE oraz łączenia tabel w JOIN.
Jak funkcje wpływają na wydajność:
- Funkcje w klauzulach WHERE i JOIN, takie jak UPPER(), LOWER(), itp., mogą wymusić na bazie danych przetwarzanie każdego wiersza, co spowalnia zapytanie.
- Jeśli zastosujesz funkcję do kolumny, która jest indeksowana, baza danych może nie być w stanie efektywnie wykorzystać indeksu. Na przykład, WHERE LOWER(nazwa_kolumny) = ‘wartość’ może zignorować indeks na polu nazwa_kolumny.
Jak unikać problemów:
- Normalizuj dane przy ich ładowaniu: Rozważ normalizację danych w momencie ich wstawiania (np. zamiana wszystkich wartości na małe litery) lub przechowuj już przetworzone wartości w oddzielnych kolumnach.
- Wykorzystaj kolumny pomocnicze: Możesz dodać kolumny pomocnicze, które przechowują przetworzone wartości, i używać ich w zapytaniach.
--Nieoptymalny przykład. Funkcja ROUND() sprawia, że baza danych nie może użyć indeksu na kolumnie salary. SELECT * FROM employees WHERE ROUND(salary, 0) > 6000;
--Optymalny przykład. W tym przypadku, jeśli salary jest zaindeksowane, baza danych może efektywnie wykorzystać indeks. SELECT * FROM employees WHERE salary > 6000;
Unikając używania funkcji w klauzulach WHERE i JOIN, możesz znacząco poprawić wydajność swoich zapytań, umożliwiając bazie danych efektywne wykorzystanie indeksów i minimalizując czas przetwarzania.
Wielkie sortowania to zło! Jak nie utopić zasobów serwera w morzu klauzuli ORDER BY
Sortowanie dużych zestawów danych przy pomocy ORDER BY może znacząco obciążyć serwer i spowolnić zapytania. Oto kilka trików, jak unikać problemów związanych z dużymi operacjami sortowania:
- Indeksy na kolumnach sortujących: Jeśli często sortujesz po określonych kolumnach, zaindeksowanie tych kolumn może znacząco poprawić wydajność. Indeksy pomagają w szybszym sortowaniu i przyspieszają dostęp do danych.
- Unikaj sortowania na dużych tabelach bez potrzeby: Staraj się unikać sortowania na tabelach z ogromnymi ilościami danych, jeśli nie jest to absolutnie konieczne. Czasami lepiej jest przetworzyć dane na poziomie aplikacji, procesu ETL lub za pomocą agregacji przed sortowaniem.

UNION ALL zamiast UNION: Oszczędzaj czas i energię serwera!
Kiedy łączysz wyniki z kilku zapytań, UNION i UNION ALL mogą mieć ogromny wpływ na wydajność. Wybór między nimi może decydować o tym, czy Twoje zapytania będą działały jak błyskawica, czy jak żółw.
Różnice między UNION a UNION ALL:
- Union
- Funkcja: Usuwa duplikaty z wyników.
- Wydajność: Może być wolniejsze, ponieważ baza danych musi dodatkowo przetworzyć i usunąć duplikaty.
- Zastosowanie: Używaj, gdy potrzebujesz unikalnych wyników i jest to istotne dla Twojego zapytania.
- Union ALL
- Funkcja: Łączy wyniki bez usuwania duplikatów.
- Wydajność: Zwykle szybsze, ponieważ nie wymaga dodatkowego kroku przetwarzania duplikatów.
- Zastosowanie: Wybieraj, gdy duplikaty są dopuszczalne lub gdy zależy Ci na lepszej wydajności i pełnym połączeniu wyników.
Kiedy używać UNION ALL:
- Brak potrzeby usuwania duplikatów: Jeśli nie zależy Ci na eliminacji powtarzających się wierszy i chcesz poprawić wydajność.
- Dane są unikalne: Gdy wiesz, że zestaw danych z każdego zapytania jest już unikalny, użycie UNION ALL jest bardziej efektywne.
Testuj różne podejścia: Sprawdź, jak UNION i UNION ALL wpływają na wydajność w Twoim konkretnym przypadku.
--Nieoptymalny przykład. --Jeśli wiesz, że sales_2023 i sales_2024 mają unikalne sales_id, UNION dodaje niepotrzebny krok usuwania duplikatów SELECT sales_id FROM sales_2023 UNION SELECT sales_id FROM sales_2024;
--Optymalny przykład. --UNION ALL działa szybciej, łącząc dane bez dodatkowego przetwarzania. SELECT sales_id FROM sales_2023 UNION ALL SELECT sales_id FROM sales_2024;
LIKE naucz się optymalnie używać znaków wieloznacznych
Optymalizacja zapytań SQL, w tym użycie operatora LIKE, jest kluczowa dla zwiększenia wydajności. Operatory LIKE ze znakami wieloznacznymi (wildcard characters) % i _ są jak magia w SQL – działają cuda, ale źle używane mogą sprawić nam wiele problemów.
Jak używać LIKE efektywnie?
- Unikaj znaków wieloznacznych na początku: Jeśli używasz LIKE
'%słowo%', baza danych nie może użyć indeksów, co prowadzi do pełnych skanowań tabeli. Stosuj znaki na końcu, np, LIKE'słowo%', aby umożliwić wykorzystanie indeksów, jeśli są dostępne. Jeśli na początku wyrażenia umieścisz % wyszukiwanie takie można porównać do szukania w całej encyklopedii haseł, które zawierają w sobie wyrażenie ,,słowo” nie wiadomo, na której pozycji. Prowadzi to do przeglądania wszystkich haseł. - Optymalizuj wzorce: Im bardziej precyzyjne wzorce, tym szybciej baza danych znajdzie wyniki. Zamiast używać szerokich wzorców, staraj się precyzować zapytania.
- Rozważ alternatywy: Jeśli możesz, użyj pełnotekstowego wyszukiwania zamiast LIKE, szczególnie w przypadku dużych zbiorów danych. Indeksy pełnotekstowe są znacznie szybsze w przeszukiwaniu tekstów.

Podsumowanie
Optymalizacja zapytań SQL to proces, który warto przeprowadzać na bieżąco, szczególnie gdy zauważasz, że Twoja baza danych zaczyna działać wolniej, a zapytania zajmują coraz więcej czasu. Spróbuj wykonać audyt zapytań na systemie, a następnie wdrożyć powyżej przedstawione techniki w celu długoterminowej poprawy wydajności bazy danych. Pamiętaj, że w obliczu rosnącej ilości danych, optymalizacja zapytań SQL staje się nieodzownym elementem pracy z bazami danych.
Najważniejsze co musisz zapamiętać to:
- Korzystaj jak najczęściej z planów zapytań żeby wychwytywać wąskie gardła swojego zapytania.
- Monitoruj swoje zapytanie po uruchomieniu i zobacz jak wpływa na cały system. Mam nadzieję, że nie chcesz angażować innych osób do ubicia Twojego zapytania, bo wpływa ono na pracę innych osób. Szczególnie w nocy, kiedy wszyscy chcą odpocząć.
- Po wykonanej optymalizacji sprawdź czy zapytanie zwraca taki sam wynik. W końcu chcesz jedynie przyśpieszyć zapytanie, a nie zmienić jego rezultat.
Mam nadzieję, że te techniki pomogą Ci przyspieszyć Twoje zapytania SQL i ułatwią codzienną pracę. Pamiętaj, optymalizacja to proces ciągły, a małe zmiany mogą prowadzić do wielkich rezultatów.
Jeśli znasz inne sposoby optymalizacji zapytań SQL, które mógłbym dodać do artykułu lub chciałbyś podzielić się swoimi doświadczeniami śmiało zostaw komentarz.
Powodzenia w optymalizacji i do zobaczenia przy kolejnym wpisie!
Dobrego dnia
Krzysiek Koszela
